



通过一个略微复杂的案例去测试几种爬虫思路的效率
- 普通requests库
- asyncio+aiohttp异步
- 多线程+多进程
爬取思路
分为两层爬取,第一层是包含每个美剧基本信息的网页,第二层是单个美剧网页其中也包含着我们要爬取的迅雷link链接。
第一层
第一层
第二层
第二层
普通requests和多进程+多线程
参考博客:http://tonghao.xyz/archives/139/
asyncio+aiohttp异步
# pip3.7 install -i https://pypi.doubanio.com/simple/ 包名
# -*- coding: utf-8 -*-
# @Time : 2021/1/13 14:39
# @Author : Tong_Hao
import re,requests,json,time,pymysql,asyncio,aiohttp
db = pymysql.connect(host='localhost', port=3306, user='root', passwd='zjh123456', db='美剧迅雷链接')
headers = {
'Cookie': 'yyetss=yyetss2020; Hm_lvt_68b4c43849deddc211a9468dc296fdbc=1608692874,1608731298,1608989825,1608990438; Hm_lvt_165ce09938742bc47fef3de7d50e5f86=1608692874,1608731298,1608989825,1608990438; Hm_lpvt_68b4c43849deddc211a9468dc296fdbc=1608990806; Hm_lpvt_165ce09938742bc47fef3de7d50e5f86=1608990806',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
# ===============正则规则
pattern = re.compile('<ul class="nav navbar-nav">(.*?)</ul>',re.S)
pattern2 = re.compile('<a href="(/list-.*?)"',re.S)
# 每个类别的 url 【navigation -> 导航栏】
navig_list = []
# 初始url,用于获取导航栏url
url_head = 'http://yyetss.com'
url1 = 'http://yyetss.com/list-lishi-all-1.html'
def get_navig(url):
global navig_list
resp = requests.get(url,headers)
if resp.status_code == 200:
print("获取导航栏成功")
html = resp.text
text = re.search(pattern,html).group()
navig_list = map(lambda x:url_head + x,re.findall(pattern2,text))
return navig_list
else:
print("获取导航栏失败")
return []
# 获取每个类别的 页数和单独的美剧->获取数据data
async def get_html(url):
# 获取页数
pattern = re.compile('<ul class=\'pagination\'>.*?<a href=.*?>(\d+)页</a></li></ul>',re.S)
pattern2 = re.compile('<div class="col-xs-3 col-sm-3 col-md-2 c-list-box">.*?<a href="(.*?)" title="(.*?)"',re.S)
# resp = requests.get(url,headers)
async with aiohttp.ClientSession(headers=headers) as ss:
async with ss.get(url) as resp:
text = await resp.text()
if resp.status == 200:
pages = eval(re.search(pattern,text).group(1))
url_ = re.sub('\d','{}',url)
# url_ http://yyetss.com/list-lishi-all-{}.html
for page in range(1,pages+1): # 页数循环
time.sleep(1)
print("===================第 <{}> 页==================".format(page))
url_page = url_.format(page)
# url_page http://yyetss.com/list-lishi-all-1.html
async with aiohttp.ClientSession(headers=headers) as ss:
async with ss.get(url) as resp2:
text2 = await resp2.text()
if resp2.status == 200:
link_title_list = re.findall(pattern2, text2)
for item in link_title_list: # 每页上单个美剧的循环
# 每个片的url
link = url_head + item[0]
title = item[1]
await get_link(link, title)
print(len(link_title_list))
async def get_link(url,title):
pattern = re.compile('<p>地址列表1:</p>.*?<ul>.*?<li><a href="(.*?)".*?</li>.*?<li><a href="(.*?)".*?</li>.*?</ul>',
re.S)
pattern2 = re.compile('<li><a href="(.*?)".*?</li>', re.S)
async with aiohttp.ClientSession(headers=headers) as ss:
async with ss.get(url) as resp:
text = await resp.text()
if resp.status == 200:
if re.findall(pattern, text):
magnet = re.search(pattern, text).group()
magnet = re.findall(pattern2, magnet)
cursor = db.cursor()
for i in range(len(magnet)):
# 保存数据
await soucre(i,title,cursor,magnet)
# print("标题:",title)
# print("迅雷个数:",len(magnet))
else:
magnet = "暂无资源"
async def soucre(i,title,cursor,magnet):
title_ji = title + '-第{}集'.format(i + 1)
sql = 'insert into {table}(title,link) values(%s,%s)'.format(table='异步')
args = (title_ji, magnet[i])
try:
cursor.execute(sql, args=args)
db.commit()
print(title_ji, "成功插入")
except Exception as e:
db.rollback()
print(e)
print(title_ji, "插入失败")
if __name__ == '__main__':
begin_time = time.time()
navig_list = get_navig(url1)
# 事件循环
loop = asyncio.get_event_loop()
tasks = [get_html(url) for url in navig_list]
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - begin_time)
耗时:大约4000s,只简单的看了一下没有让程序跑完
各程序运行时的CPU使用率
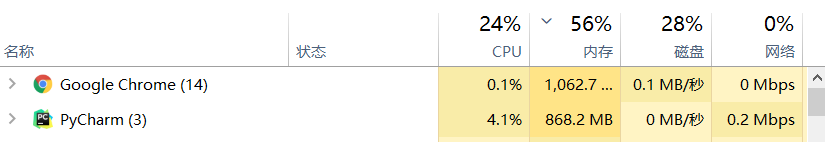


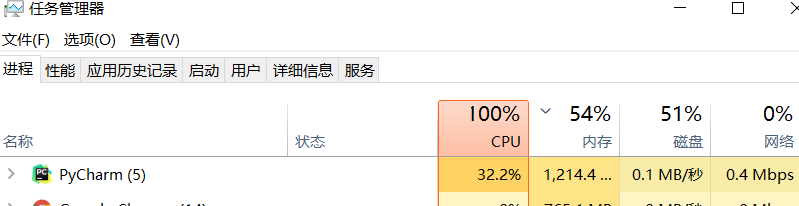
小结
根据上一篇的asyncio+aiohttp实现异步爬虫的性能来看在简单爬虫任务下的异步爬虫效果不错效率提升很大。但在此案例中却远不及多进程+多线程的速度,那么对于异步,多线程,多进程的抉择问题上就遵循以下原则:
if io_bound:
if io_slow:
print('Use Asyncio')
else:
print('Use multi-threading')
else if cpu_bound:
print('Use multi-processing')
所念皆星河
切换主题 | SCHEME TOOL
Comments | NOTHING