




数组的索引,切片
ndarray[a,b,c...]根据数组的维数来看
a = np.array([[1,2,3],
[4,5,6]]) #二维
b = np.array([
[[1,2,3],
[4,5,6]],
[[7,8,9],
[10,11,12]]
]) #三维
print(a[0,0])
print(b[1,1,2])
>>>
1
12修改数组形状
ndarray.reshape(new_shape)
- 返回一个新的数组对象
ndarray.reshape(想要修改的形状),但要保证修改后的形状是有意义的,比如你原来的数组形状是[3,3],你使用ndarray.reshape([2,5])很明显整除不了,会报错。如果某个参数为 -1,那么会自动整除,也就是个待计算值。
a = np.array([[1,2,3],
[4,5,6]]) #shape是[2,3]
b = np.array([
[[1,2,3],
[4,5,6]],
[[7,8,9],
[10,11,12]]
]) #shape是[2,2,3]
a.reshape([3,2])
b.reshape([3,-1])
>>>
array([[1, 2],
[3, 4],
[5, 6]])
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])ndarray.resize(new_shape)
修改数组本身的形状,(需要保持元素个数前后想同),使用方法也和ndarray.reshape(new_shape)一致。
修改数组元素类型
ndarray.astype(np.int64)
同样是返回一个新的数组对象
a = np.array([[1,2,3],
[4,5,6]]) #二维
b = a.astype(np.float32)
b.dtype
>>>
dtype=float32数组的去重
np.unique(ndarray对象)
返回一个新的数组对象
a= np.array([[1,2,3,4],[3,4,5,6]])
b = np.unique(a)
b
>>>
array([1,2,3,4,5,6])创建0,1数组
- 创建0数组,np.zeros(0数组的形状)
zeros = np.zeros([2,3])
zeros
>>>
array([[0., 0., 0.],
[0., 0., 0.]])- 将数组中的数都修改成0,np.zeros_like(ndarry对象)
ones = np.ones([2,3])
ones_0 = np.zeros_like(ones)
ones_0
>>>
array([[0., 0., 0.],
[0., 0., 0.]])- 创建1数组,np.ones(1数组的形状)
ones = np.ones([2,3])
ones
>>>
array([[1., 1., 1.],
[1., 1., 1.]])- 将数组中的数都修改成1,np.ones_like(ndarry对象)
ndarray数组的生成方式
- np.array(object,dtype)
- np.asarray(ndarray对象,dtype)
第一种就是使用np.array(object,dtype)去生成,其中object对象可以是数组或者一个已经存在ndarray对象。
如果里面的参数使用的其他ndarray对象,那么生成的数组就是其参数里数组的深拷贝,原始数组的修改对其没有影响。
a = np.array([[1,2,3],[4,5,6]])
print(a)
a1 = np.array(a)
print(a1)
# a1就是a的深拷贝
>>>
[[1 2 3]
[[1 2 3]
[4 5 6]]
[4 5 6]]第二种就是使用np.asarray(ndarray对象,dtype)去生成,需要注意的是这个方法类似于copy(拷贝)中的浅拷贝。
使用asarray方法生成的 数组(as) 是原来 数组(初始) 的浅拷贝,也就是说数组(原始)的修改对其有影响,但不会影响到使用np.array(数组(初始))生成的数组(ar)。
更详细就是相当于索引的形式,并没有真正的创建一个新的。
ps:as,ar只是代表使用asarray和ar方法生成的数组别名。
a = np.array([[1,2,3],[4,5,6]])
ar = np.array(a) # ar
ass = np.asarray(a) # as
print("=====原始数组修改前====")
print(ar,'\n\n',ass)
a[0][0] = 1000
print("=====原始数组修改后====")
print(ar,'\n\n',ass)
>>>
=====原始数组修改前====
[[1 2 3]
[4 5 6]]
[[1 2 3]
[4 5 6]]
=====原始数组修改后====
[[1 2 3]
[4 5 6]]
[[1000 2 3]
[ 4 5 6]]生成固定范围的数组
1. np.linspace(start,stop,num,endpoint)
- 创建等差数组 --- 指定数量
- 参数:
start:序列的起始值
stop:序列的终止值
num:要生成的等间隔样例数量,默认50
endpoint:序列中是否包含stop值,默认true
需要注意的是,数组元素类型dtype是dtype('float64')类型
gd_1 = np.linspace(0,100,11)
print(gd_1.dtype,gd_1)
>>>
dtype('float64')
array([ 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100.])2. np.arange(start,stop,step,dtype)
- 创建等差数组 --- 指定步长
- 参数:
step:步长,和range的一样
gd_2 = np.arange(0,110,10)
print(gd_2.dtype)
gd_2
>>>
dtype('int32')
array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100])3. np.logspace(start,stop,num)
- 创建等比数列
- 参数:
num:要生成的等比数列的数量,默认50
gd_3 = np.logspace(0,2,3)
gd_3
>>>
dtype('float64')
array([ 1., 10., 100.])生成随机数组
生成随机整数数组
# 生成 40 <= x <= 100 的10行5列的二维数组
score = np.random.randint(40,100,(10,5))
>>>
array([[99, 41, 65, 87, 99],
[80, 94, 67, 72, 83],
[91, 74, 56, 90, 73],
[74, 98, 46, 70, 79],
[89, 42, 62, 79, 97],
[66, 92, 99, 98, 56],
[54, 40, 80, 87, 96],
[42, 72, 45, 40, 94],
[62, 76, 80, 80, 77],
[54, 93, 91, 47, 52]])直方图的认识
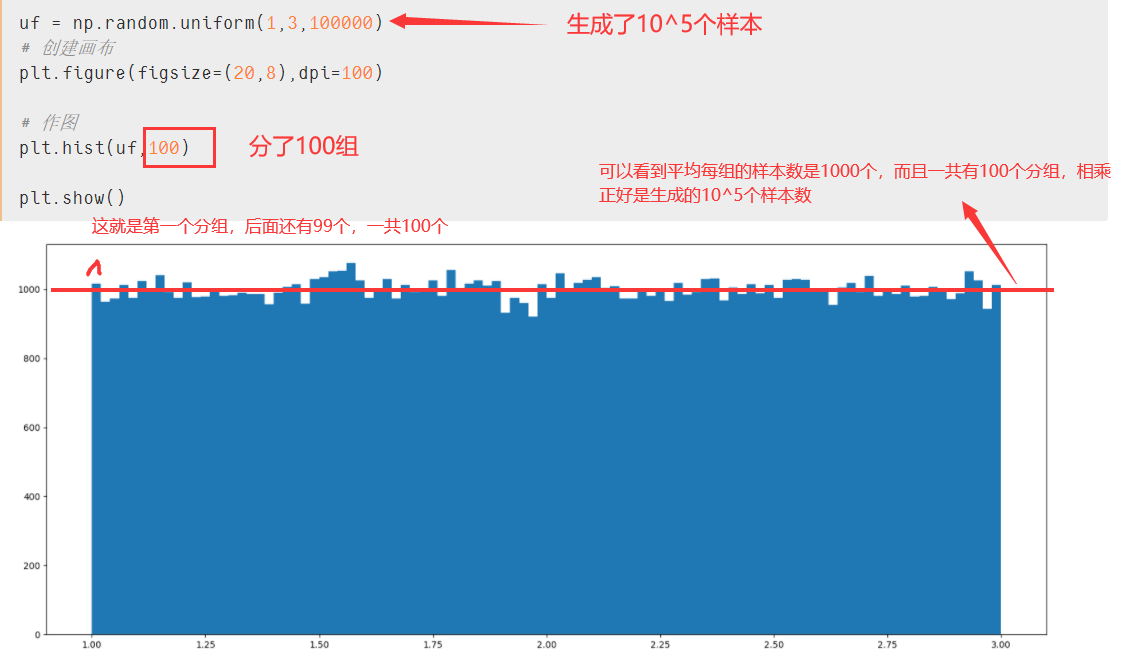
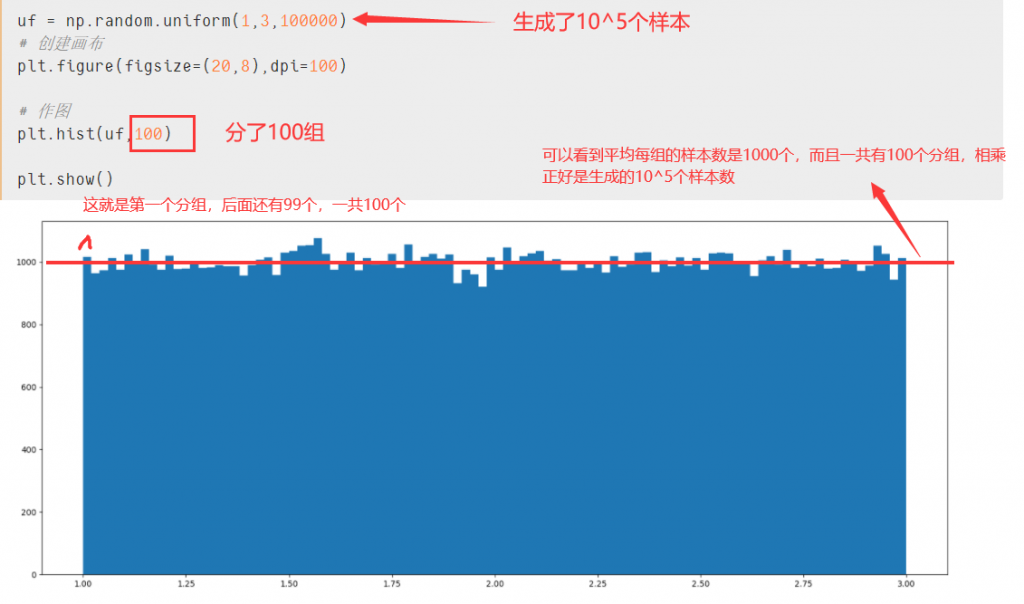
直方图,形状类似柱状图却有着与柱状图完全不同的含义。直方图牵涉统计学的概念,首先要对数据进行分组,然后统计每个分组内数据元的数量。 在坐标系中,横轴标出每个组的端点,纵轴表示频数,每个矩形的高代表对应的频数,称这样的统计图为频数分布直方图。
结合matplotlib中的plt.hist(数据,条数) 我对上面红字的理解是,根据参数中的条数去进行分组形成不同的条状(长得像柱状图但完全不一样),没个分组(也就是每个条条)的高度就是统计后每个分组内数据元的数量。拿均匀分布中的图打个比方:
正态分布(normal distribution)
np.random.normal(μ=0.0,σ=1.0,size=None)
关于size参数有两种情况:
- size是个整数:则返回一个一维ndarray类型的数组,个数就是输入值
- size是个元组:则返回一个形状和输入元组一致的数组

正态分布我们并不陌生,若随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为N(μ,σ^2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。
- μ 是正态分布的位置参数,描述正态分布的集中趋势位置。概率规律为取与μ邻近的值的概率大,而取离μ越远的值的概率越小。正态分布以X=μ为对称轴,左右完全对称。正态分布的期望、均数、中位数、众数相同,均等于μ。
- σ 描述正态分布资料数据分布的离散程度,σ越大,数据分布越分散,σ越小,数据分布越集中。也称为是正态分布的形状参数,σ越大,曲线越扁平,反之,σ越小,曲线越瘦高。
至于正态分布为什么叫normal distribution,是因为在大自然中符合这种概率分布的情况十分常见普通。身高,体重,天气之类的,所以叫做normal。
x1 = np.random.normal(2,1,1000000)
# 创建画布
plt.figure(figsize=(20,8),dpi=100)
# 作图
plt.hist(x1,100)
plt.show()

标准正态分布
numpy.random.randn(d0,d1,…,dn)
- randn函数返回一个或一组样本,具有标准正态分布。
- dn表格每个维度
- 返回值为指定维度的array
- np.random.randn() # 当没有参数时,返回单个数据
rdn = np.random.randn(100000)
plt.hist(rdn,1000)
plt.show()
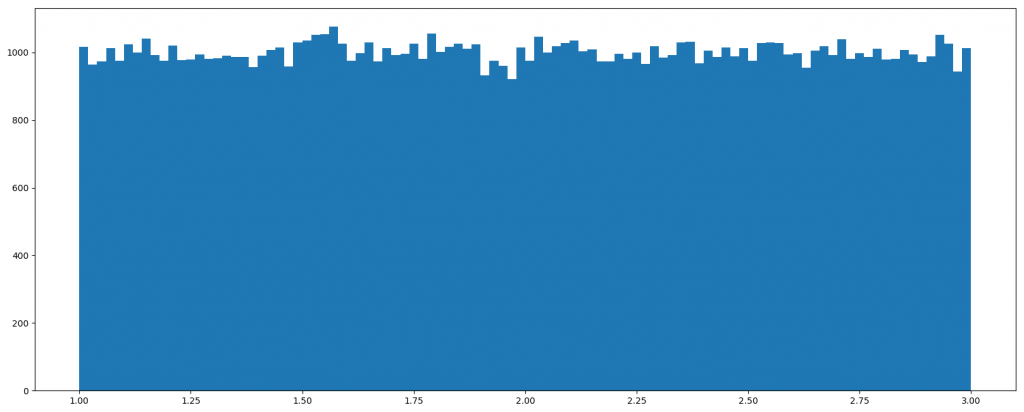
均匀分布
np.random.uniform(low=0.0,high=1.0,size=None)
- 功能:从一个均匀分布(一个上下限分别为low,high的矩形)中随机采样,注意定义域是左闭右开,即包含low,但不包含high
- 参数:
low:采样下界,float类型,默认0
high:采样上界,float类型,默认1
size:输出样本数目,int或元组(tuple)类型,例如 size=(m,n,k),则输出mnk个样本,缺省时输出一个值 - 返回值:返回一个ndarray类型,其形状和size中一致
uf = np.random.uniform(1,3,1000000)
# 创建画布
plt.figure(figsize=(20,8),dpi=100)
# 作图
plt.hist(uf,100)
plt.show()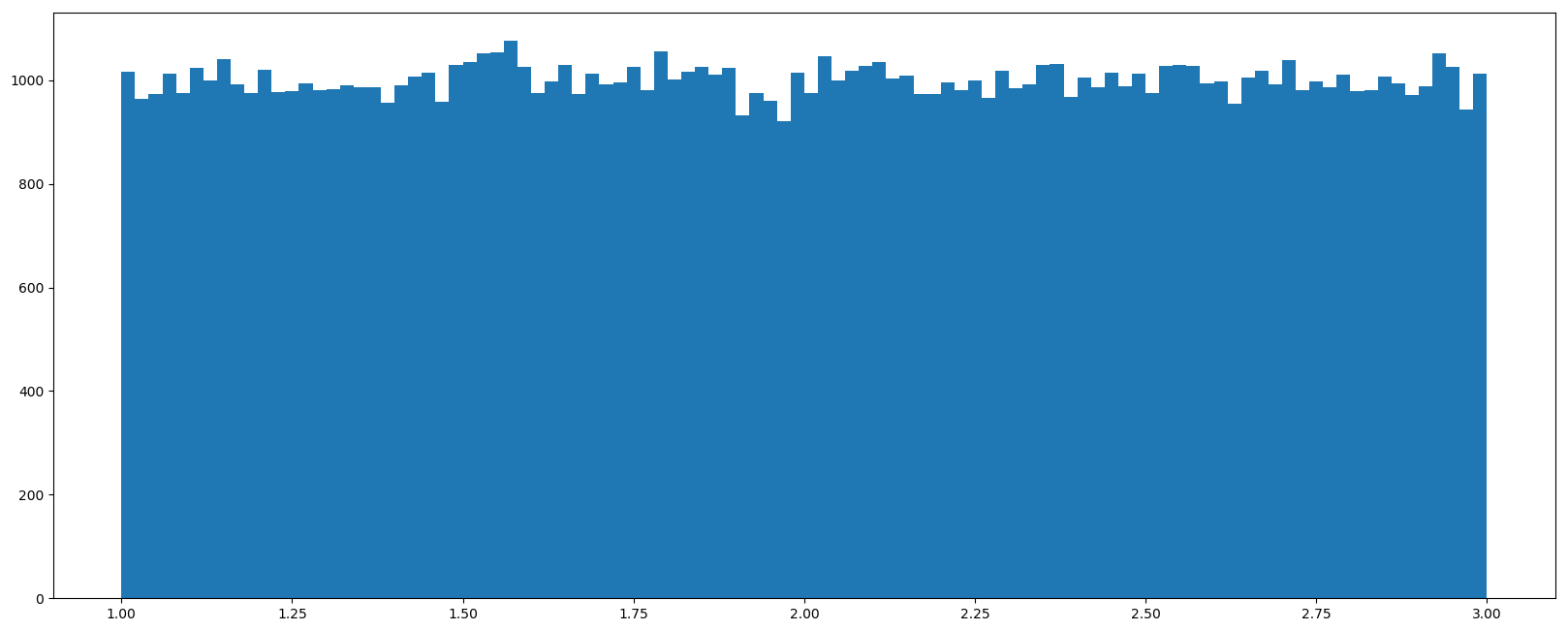

Comments | NOTHING