




基本数据操作
- data.drop('date', axis=1, inplace=True)
删除"data"这一列,并且覆盖源数据 - data.drop(['data1','data2','data3'], axis=1, inplace=True)
删除列表内['data1','data2','data3']这些列,并且覆盖源数据 - axis=1表示列
索引操作
pandas的默认索引操作是:data[列][行]
也可以使用data.iloc[行,列]去操作数据
赋值操作

Dataframe排序
data.sort_values(by=列名,ascending=True)
ascending=True为升序,Flase为降序,data.sort_values()支持多列排序,规则是若第一个列值相等,则比较第二个列值。
单列,data.sort_values(by="open", ascending=False).head()
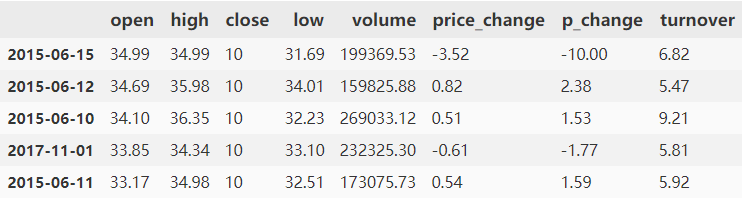
多列,data.sort_values(by=["open", "high"]).head()
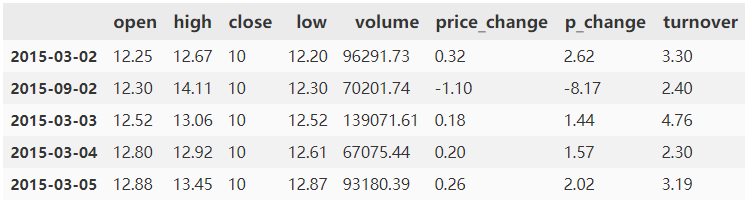
data.sort_index()
对索引进行排序,也就是行
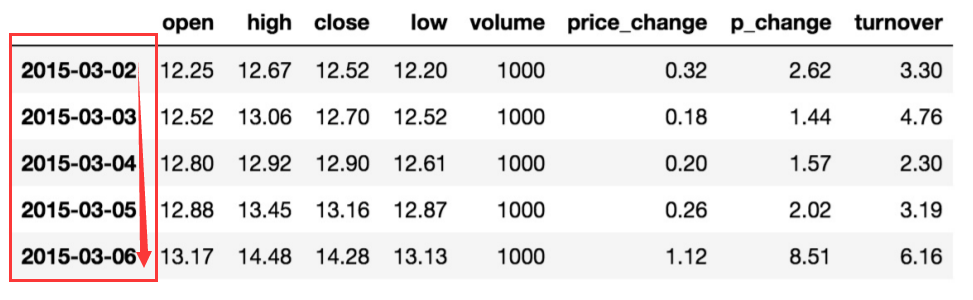
小结

Dataframe的运算
算术运算
data[列名].add(10),该列的数值都加10。
data["open"].add(10).head()逻辑运算
我感觉data[ ]这个框框里应该是布尔型,True的就展示,Flase就忽略
data[data["open"] > 23].head()
可以直接用 >,<,==这些常见的逻辑运算符号。
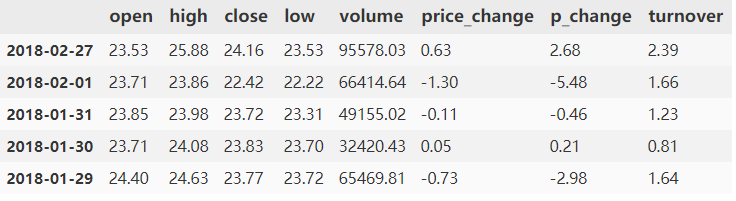
data[(data["open"]>23)&(data["open"]<24)].head()
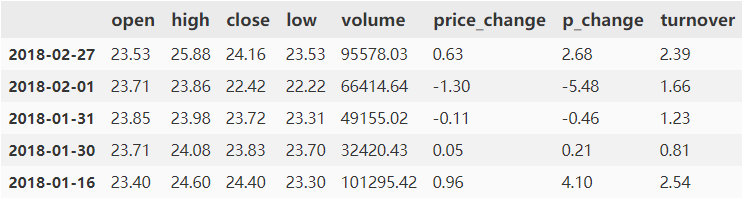
data.query("open<24 & open>23").head()
也可以使用data.query(字符串的形式去表达逻辑运算),效果和直接用逻辑运算符号一样
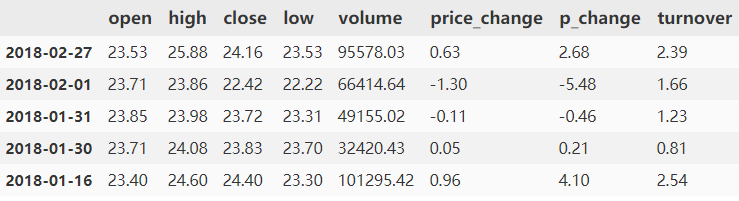
data[data["open"].isin([23.23, 23.71])]
.isin(列表),列表里存放需要从data里判断是否存在的值,也很好用,和in关键字差不多

统计运算
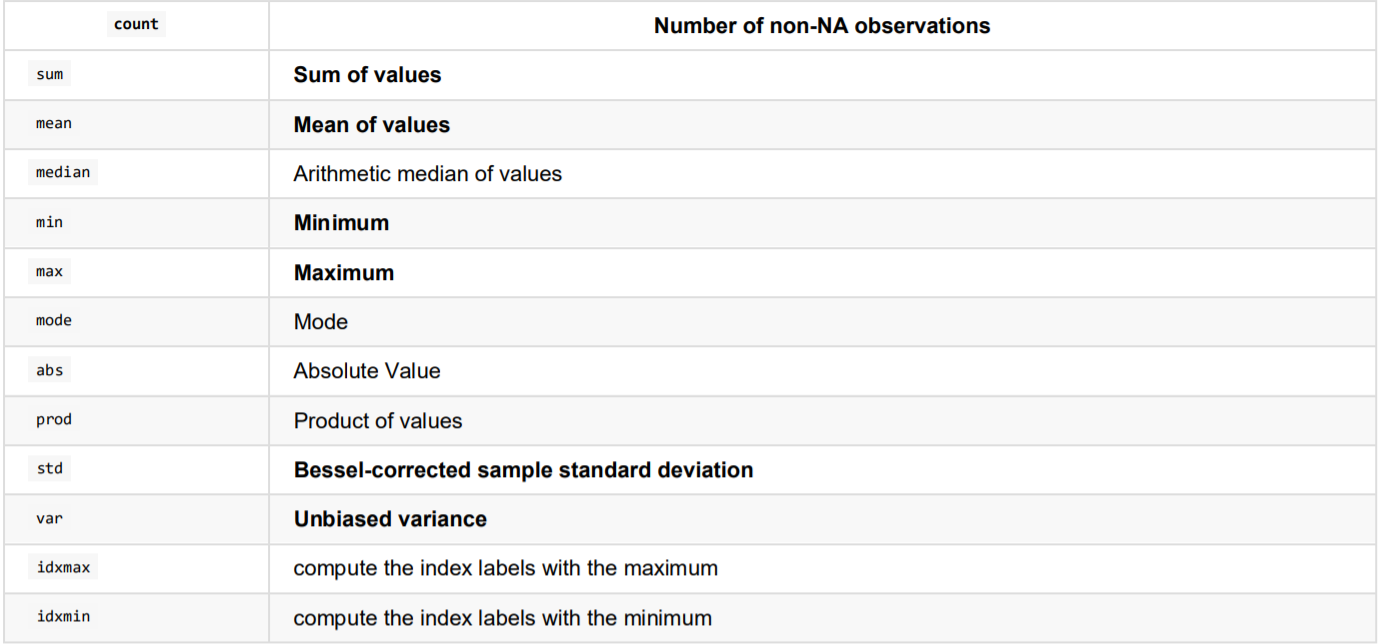
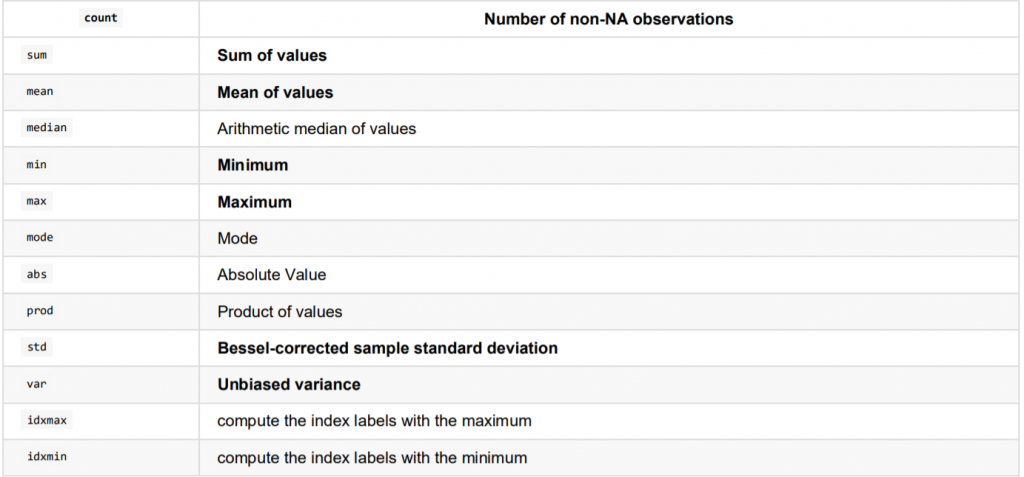
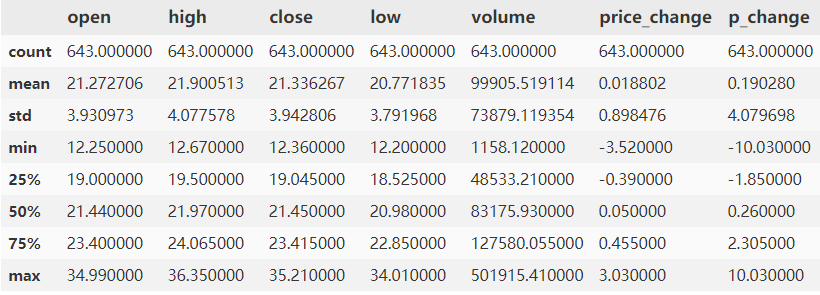
最常用的data.describe(),整体数据概况
data.describe()
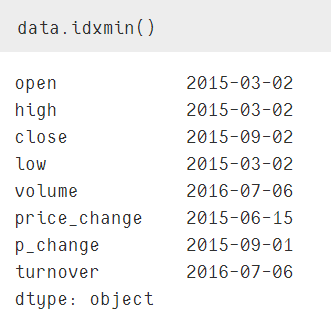
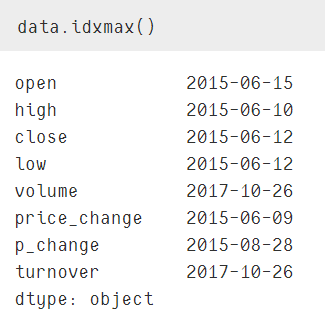
data.idxmax()和data.indxmin()
获取最大值的行索引值
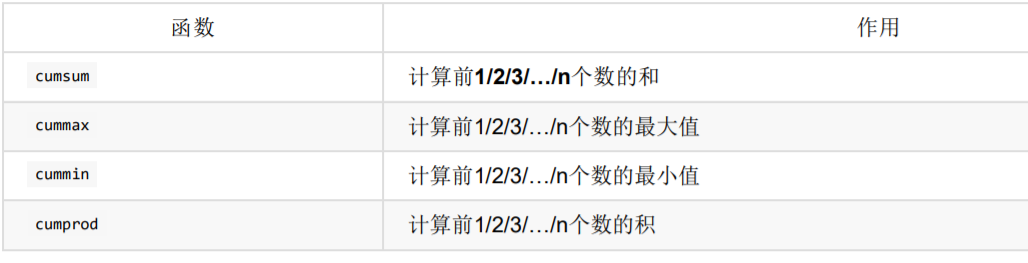
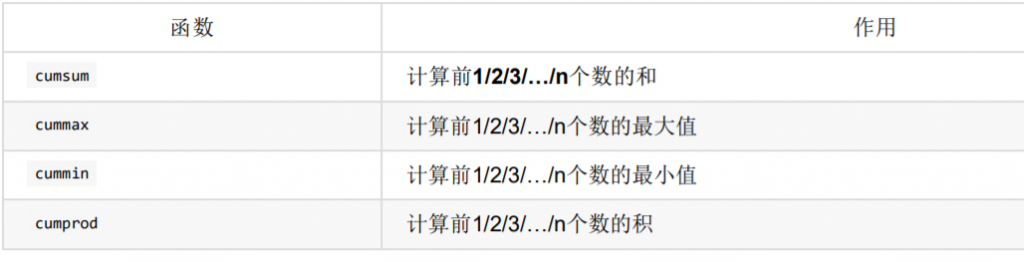
累计统计函数
data.cumsum()去展示
stock_rise = data["p_change"]
stock_rise.cumsum().plot()
plt.show()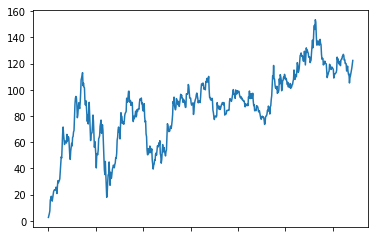
自定义运算
- apply(func,axis=0)
func:自定义函数
axis=0:默认是列,axis=1为行进行运算 - 定义一个对列,最大值 - 最小值 的函数
data[["open", "close"]].apply(lambda x: x.max()-x.min(), axis=0)
小结


Comments | NOTHING